- Published on
Performance testing 101
- Authors

- Name
- Aleksandar Zeljković
- @a_zeljkovic
During the last decade, performance testing is becoming a more and more important topic within development teams. An all-time high number of users are using internet applications, systems are getting extremely complex and the amount of data sent over the internet and processed by different computing resources is insane. The rise of cloud computing gave an opportunity to a lot of middle and small businesses to provide their services over the world wide web thanks to cheap and scalable compute machines, serverless or different types of managed services. On the other side, users are becoming very demanding in terms of reliability and speed of web services, so every outage and performance degradation will hardly be forgiven. For that reason, if your business relies on a web application, service, API, or similar, you need to start thinking about the performance capabilities of your application and infrastructure ASAP. This article will give you a brief overview of terms, metrics, and activities which will, hopefully, give you a hint on where to start with the implementation of performance testing in your team.
What is performance testing?
Despite the fact that there is a variety of different types of performance testing in the software industry, the term performance testing usually describes the set of actions used to uncover the behaviour of a certain web application under a certain load. As I already mentioned, we are living in an era when people heavily depend on a variety of internet services. Application inability to handle a certain amount of users can have multiple manifestations and technical consequences to your application, which can further lead to a loss of customers and profit.
Performance testing is often used as an umbrella term for different types of testing which are differentiated by the load parameters and type of the issues that can be uncovered. The most common types of performance testing are:
- load testing – the process of putting an application under usual/intermediate load in order to make sure it is capable of serving users in typical day-to-day conditions.
- stress testing – during a stress testing system is being pushed over the usual load to check how the system behaves in these conditions. If we want to know how will the system behave and recover when it reaches the breaking point, we can go a step further and continue increasing the load until the system fails.
- spike testing – unlike stress testing, spike testing is generating periodic spikes of an unusually high load. Spikes are intensive but short, and this type of performance test should uncover issues related to highly variable load.
- soak testing – opposite to spike testing, soak testing is putting the system under long-running, continuous intermediate load. Problems that may be exposed with this type of test are usually memory leaks, connection issues, storage, DB overload, etc…
- scalability testing – the process of increasing and decreasing load in order to verify infrastructure capability of scaling up or down.
- volume testing – verifying the system’s ability to process a large amount of data or files without significant delay, data loss, or any other issues.
Prerequisites for performance testing
Before we start with the implementation of performance testing, we need to be aware of the necessary requirements. Prerequisites for performance testing can be divided into five main categories:
- performance testing tool – first criteria for performance testing tool selection is a price. Paid tools are usually bundled with certain load generation capacity and easier configuration. Other criteria for tool selection are the following:
- code vs codeless tools
- programming language
- resource utilization
- supported protocols
- result visualisation
- CI/CD integration – this is the interface where the test process will be triggered from, and where team will be able to see clear and concise report and resume of the performance testing jobs
- application under test configuration – unlike functional testing, performance testing requires great caution in term of AUT configuration.
- application needs to be configured as close as possible with production application (debugging, services, etc)
- infrastructure needs to match the production instance as well (resources, autoscaling, geographic location, etc.)
- amount of data used in testing needs to represent the realistic volume and throughput
- load generator – depending of the desired amount of simulated users or data, certain compute power will need to be provided and configured with the purpose of load generation
- monitoring – knowing basic performance testing metrics is not sufficient for a deeper understanding and troubleshooting of application under test. If want to have a complete overview of what was happening during the performance testing process, we need to set up the proper monitoring around our AUT infrastructure so we can identify bottlenecks. It is also recommended to monitor the load generators, so we can know if bad results are caused by insufficient or drained compute capacity.
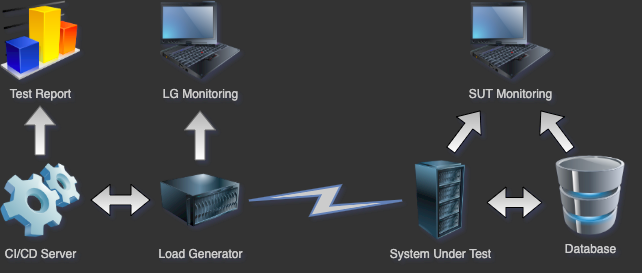
Configuration, metrics and analysis
The first step in a performance testing strategy preparation is the assessment of performance-related application risks. In the ideal case, all performance testing types should be exercised, but in real-world conditions, this is not always possible due to a lack of time, skills, money, etc. In that case, the development team should be aware of the risk impact (for different performance issue types), and testing models should be prioritized accordingly.
As we can see from the previous section, testing types are primarily differentiated by the number of virtual users (VUs) and the duration of test stages. Therefore, the starting point for test configuration is the number of users/requests that we are having on our production system via analytics/monitoring service. Depending on the test type you want to exercise, a higher or lower amount of VUs will be used combined with execution time and ramp up/down stages.
As soon as we have the numbers that define load amount and shape, we need to define pass/fail criteria for our performance tests. This is done through the configuration of the expected response time (either total or separated by communication segments), the number of errors received from the server, etc.
Once we have the results from the performance testing job, if tests are failing, further investigation needs to be performed. The first thing that needs to be eliminated is the eventual load generator bottleneck. If the load is too high for a given infrastructure or there were glitches or degradations on the “client” side, we need to make sure to remove them in order to get credible results. Very often test teams do not pay enough attention to the load generator performance issues (or misconfiguration) thus losing time and money trying to identify nonexistent issues in their app.
As soon as we eliminated client-side issues as a performance degradation reason, we can start the application troubleshooting process. Monitoring should help with the approximation of the root cause, but further investigation will probably have to be performed. Since there is a variety of reasons why performance issues may exist in the application (compute power, database, network, storage, server, queries, libraries, etc.), most likely the whole team will need to be included in the investigation procedure.
Conclusion
The two most common mistakes of development teams related to performance testing are:
- Completely overseeing/ignoring performance testing
- Underestimating effort and costs related to performance testing
Despite the fact that performance testing might look trivial from a high-level perspective, there is a lot of moving parts in a properly built performance testing system:
- performance testing tool
- test configuration
- load generation and distribution
- application under test
- monitoring
Proper performance testing is an iterative process that requires deep product analysis, technical preparation, and detailed monitoring. This will require significant investment in tools, skills, and infrastructure, but these costs will, at the end of the day, be significantly lower than the potential damage and profit loss caused by the inadequate performance capabilities of your application.